Scoring
Four dimensions of quality.
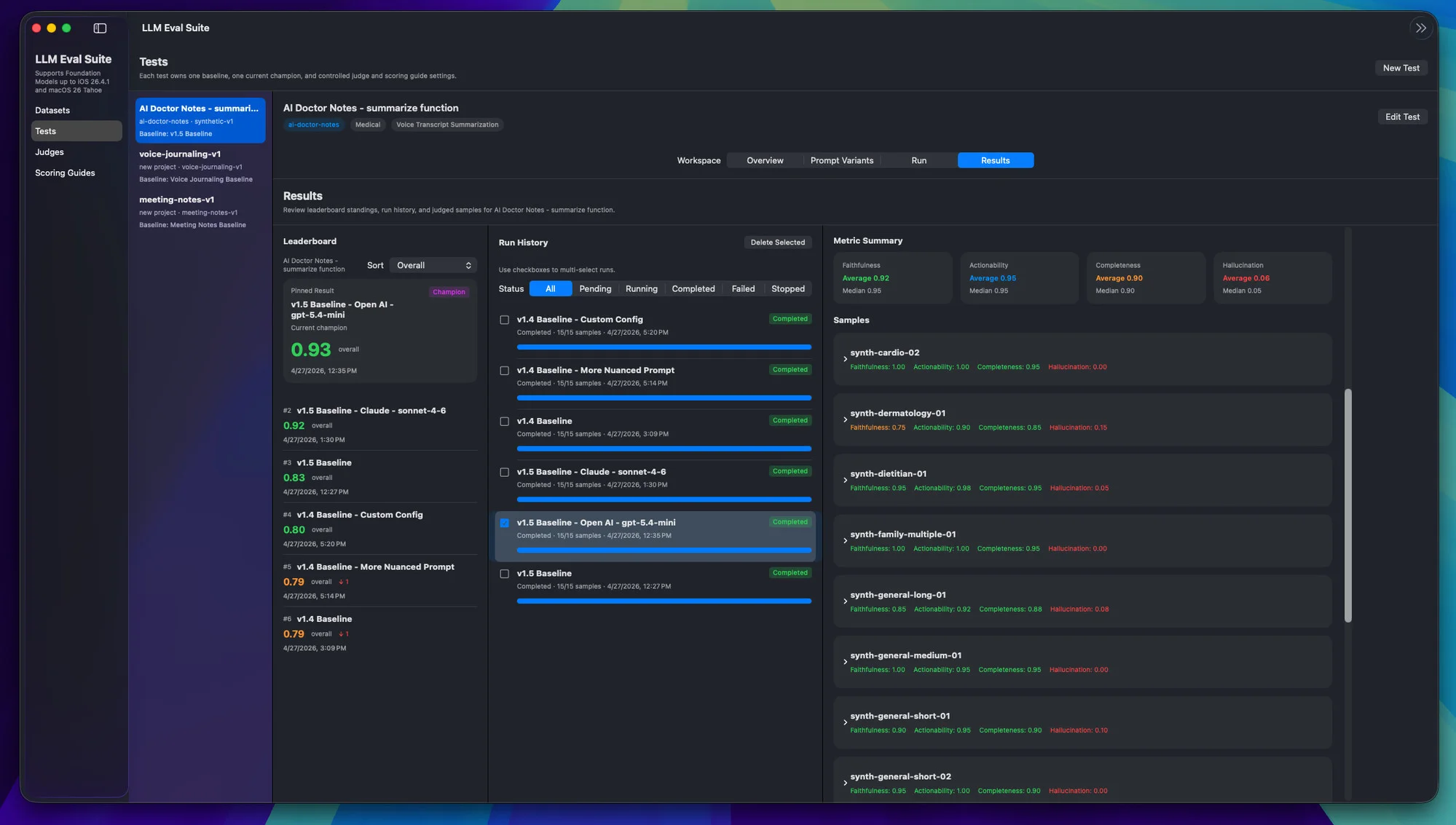
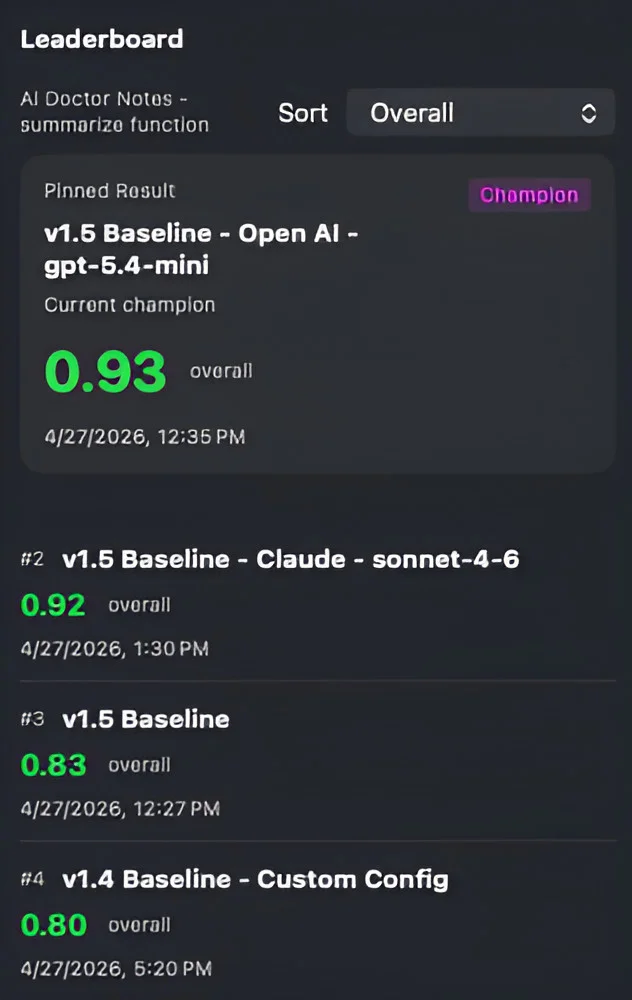
Every output is judged on four scores. Together they tell you what's working and what needs attention.
1.0
Faithfulness
Does the output stay true to the source? Deduct for invented events, claims, or interpretations. 1.0 = perfectly grounded.
1.0
Actionability
Is it useful when you need to act later? Reward clear next steps and commitments. 1.0 = immediately useful.
1.0
Completeness
Are the key points and context captured? 1.0 = nothing important left out.
0.0
Hallucination
How much is fabricated or unsupported? 0.0 = nothing, 1.0 = everything.