LLM Eval Playbooks
Browse practical clusters for shipping AI features: find the right use case, start your first eval, design a scoring system, or compare Apple Foundation Models with cloud LLMs.
Featured decision guide
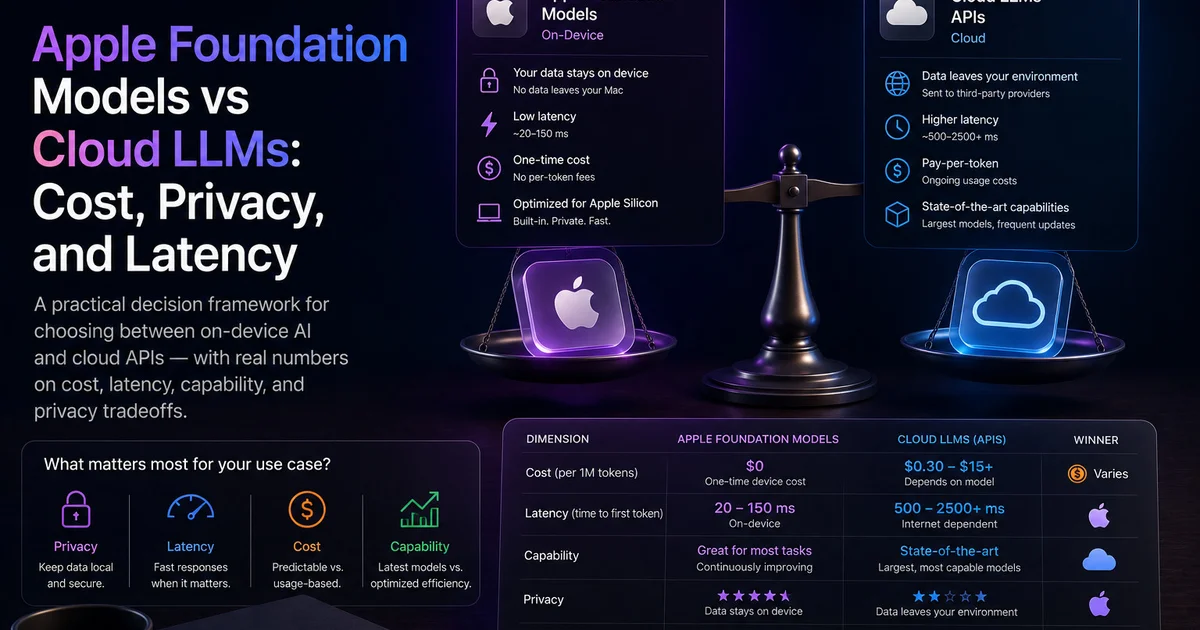
Compare on-device AI with cloud APIs across capability, privacy, latency, and cost before you choose an architecture.
Reading paths
The same article library is organized into decision paths, so you can move from the immediate question to the next supporting concept without hunting through a chronological archive.
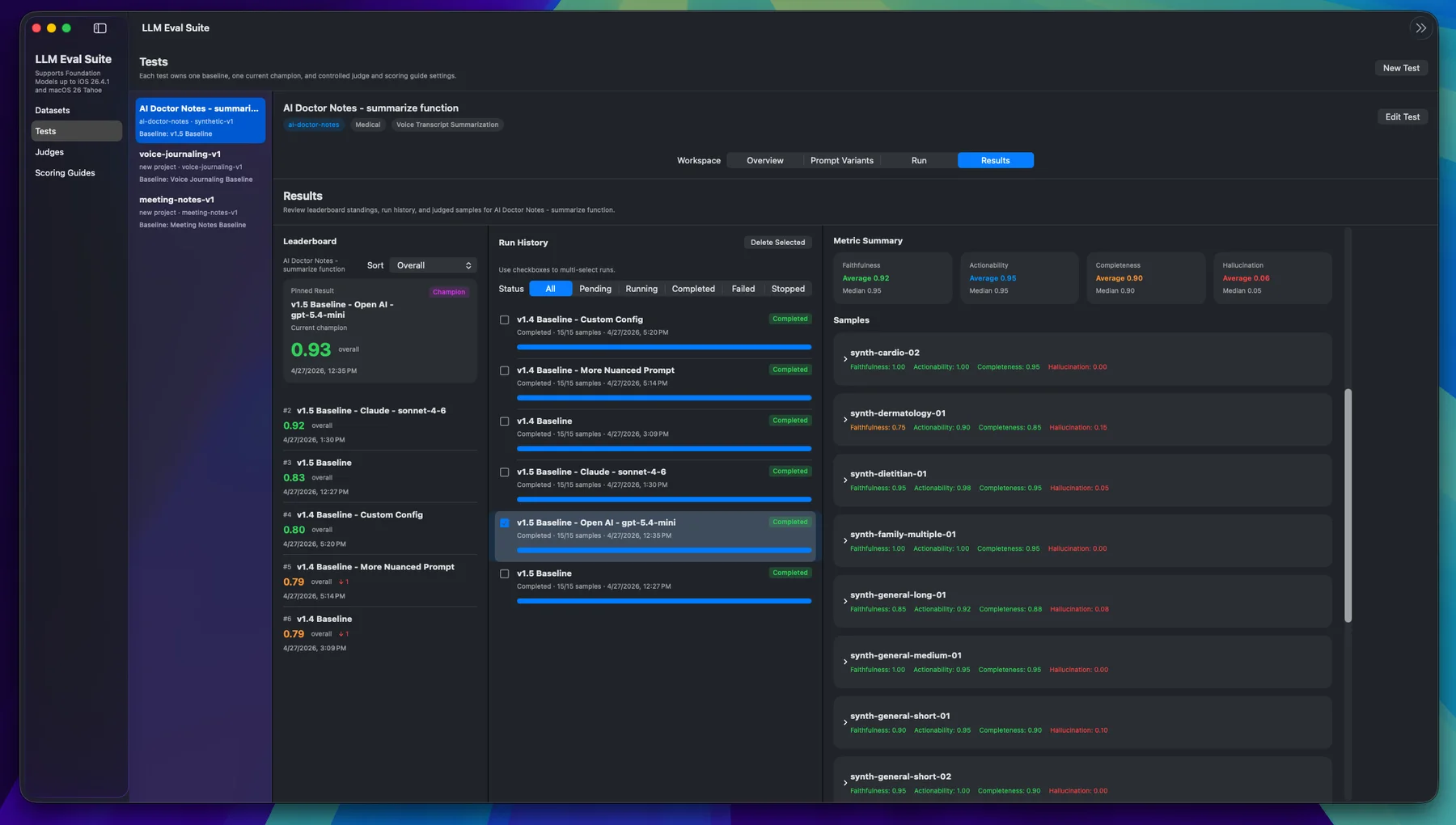
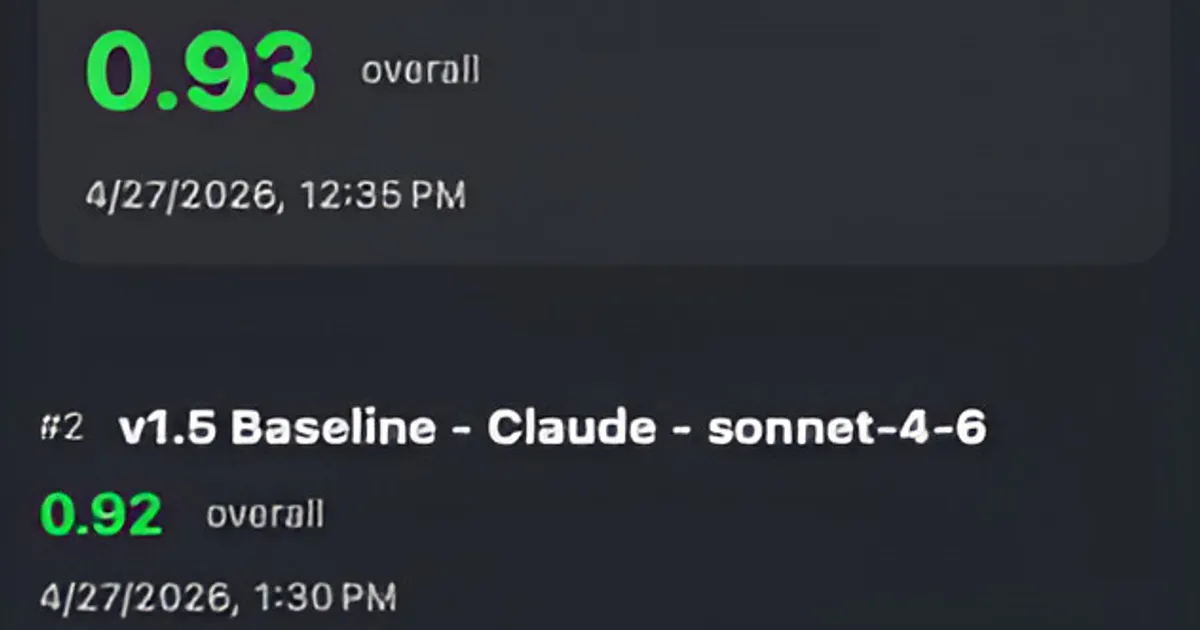
See the product scenarios LLM Eval Suite is built for, then jump into a real case study on improving AI Doctor Notes.
Pillar
See practical ways to use structured evaluation for prompt variants, transcript summaries, model comparisons, and production AI quality.
May 11, 2026 / 5 min read

Opinion
Understand why informal prompt testing misses real-world failures and how structured scoring catches them before release.
9 min read
Tutorial
Set up a repeatable evaluation workflow with a dataset, prompt variants, judge configuration, and scoring results.
8 min read
Create your first test, understand why the process matters, then learn how a judge should score the results.
Pillar
Set up a repeatable evaluation workflow with a dataset, prompt variants, judge configuration, and scoring results.
May 9, 2026 / 8 min read

Guide
Learn how judge models score AI outputs consistently across faithfulness, actionability, completeness, and hallucination.
12 min read

Guide
What an LLM evaluation framework is, what it should measure, and how LLM Eval Suite operationalizes structured AI evaluation.
10 min read
Define the dimensions of quality, build a dataset that represents reality, and tune the scoring guide to your domain.

Pillar
A deeper look at the four quality dimensions that turn subjective AI output review into a measurable system.
May 10, 2026 / 14 min read

Guide
Design representative, balanced, and maintainable datasets so your eval scores reflect production behavior.
11 min read

Guide
Pick the rubric and strictness level that matches your use case so the judge rewards the behavior users need.
8 min read
Understand the on-device evaluation workflow, then compare Apple Foundation Models with cloud providers.

Pillar
Run structured evaluations against Apple Intelligence Foundation Models directly on a Mac with practical setup guidance.
May 10, 2026 / 10 min read
Comparison
Compare on-device AI with cloud APIs across capability, privacy, latency, and cost before you choose an architecture.
12 min read

Comparison
How to compare AI model outputs in a repeatable, product-relevant way that is more useful than generic benchmark tables.
11 min read
Set up a prompt testing workflow with a dataset, scoring guide, and leaderboard to track quality over time.

Pillar
How to evaluate prompt variants before release and avoid regressions when prompts, models, or scoring criteria change.
May 19, 2026 / 9 min read
Tutorial
Set up a repeatable evaluation workflow with a dataset, prompt variants, judge configuration, and scoring results.
8 min read
Guide
Learn how judge models score AI outputs consistently across faithfulness, actionability, completeness, and hallucination.
12 min read
Full library
12 articles, about 119 minutes of practical evaluation guidance.
Use Cases
May 11, 2026 / 5 min read
Tutorial
May 9, 2026 / 8 min read
Opinion
May 10, 2026 / 9 min read
Guide
May 10, 2026 / 12 min read
Deep Dive
May 10, 2026 / 14 min read
Guide
May 10, 2026 / 11 min read
Guide
May 10, 2026 / 8 min read
Tutorial
May 10, 2026 / 10 min read
Comparison
May 10, 2026 / 12 min read
Guide
May 19, 2026 / 10 min read
Guide
May 19, 2026 / 9 min read
Comparison
May 19, 2026 / 11 min read
