
Comparison
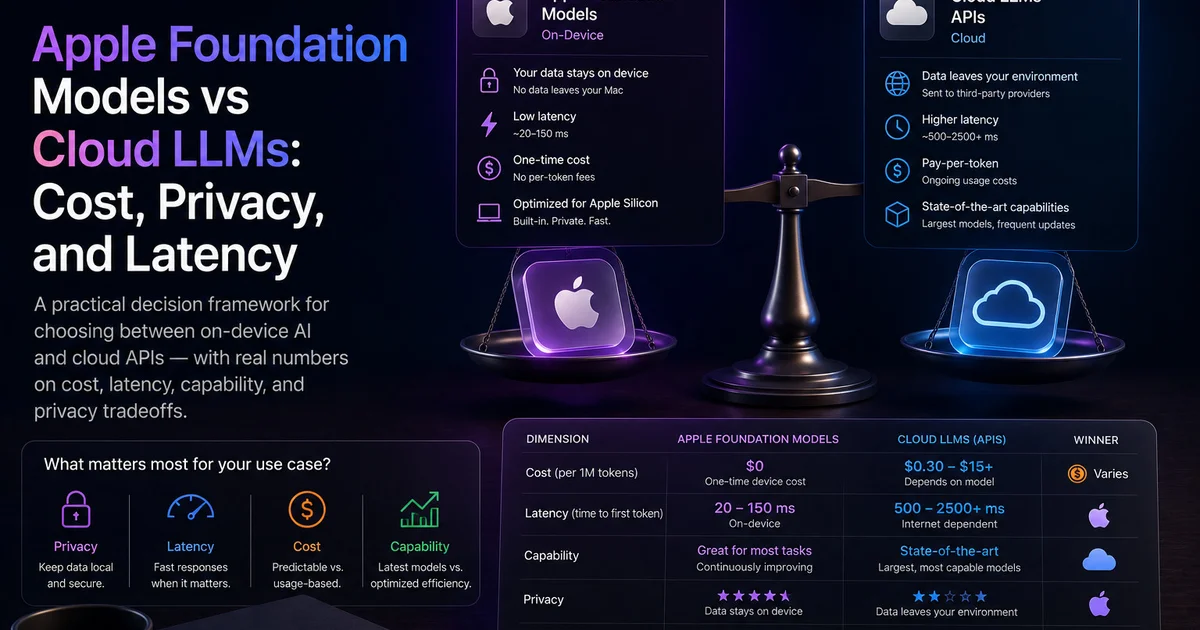
Apple Foundation Models vs Cloud LLMs: Cost, Privacy, and Latency
A practical decision framework for choosing between on-device AI and cloud APIs — with real numbers on cost, latency, capability, and privacy tradeoffs.
Building an AI-powered app? The choice between on-device Apple Foundation Models and cloud-based LLMs isn't just technical — it affects your cost structure, user trust, and competitive positioning.
This guide cuts through the marketing to give you the real numbers and tradeoffs.
"Apple's on-device models are designed to process requests entirely on device, ensuring that user data never leaves the device. This architecture provides meaningful privacy guarantees that cloud-based alternatives cannot match."
The Basics: How They Work
Apple Foundation Models run directly on user devices using the Neural Engine in Apple silicon — a dedicated accelerator that handles the matrix multiplications underlying transformer inference with minimal power draw. Apple documents the AFM family at approximately 3 billion parameters, optimized for on-device inference within a 4,096-token context window (Apple Developer Docs, 2026).
Cloud LLMs (OpenAI GPT, Anthropic Claude, MiniMax) run on remote servers and are accessed via API. Your app sends data to the cloud, the model processes it on GPU clusters, and the response returns — typically within 500ms to 4 seconds depending on provider and model variant.
Cost Comparison
Cost is where on-device AI wins decisively. According to OpenAI's pricing documentation and Anthropic's model pricing, cloud API costs vary widely by model tier (OpenAI API Pricing, 2026; Anthropic Model Catalog, 2026):
| Provider | Input Cost | Output Cost | Notes |
|---|---|---|---|
| Apple Foundation Models | Free | Free | No API costs |
| GPT-4o | $5.00/1M tokens | $15.00/1M tokens | Premium tier |
| GPT-4o mini | $0.15/1M tokens | $0.60/1M tokens | Budget tier |
| Claude Sonnet 4.6 | $3.00/1M tokens | $15.00/1M tokens | Best for complex tasks |
| Claude Haiku 3.5 | $0.80/1M tokens | $4.00/1M tokens | Fast, affordable |
| MiniMax M2.7 | ~$0.20/1M tokens | ~$0.40/1M tokens | Best value frontier |
Source: OpenAI API pricing page (2026); Anthropic Claude model pricing (2026). Apple Foundation Models: no API cost.
Real-World Math: 250M Tokens/Month
10,000 monthly active users × 50 API calls/day × 500 tokens/call = 250M tokens/month
Apple AFM: $0 |
GPT-4o ($5/$15): $3,750/month |
Claude Haiku 3.5 ($0.80/$4): $1,000/month |
MiniMax M2.7 (~$0.20/$0.40): ~$125/month
Latency Comparison
Latency affects user experience. On-device Apple Foundation Models process tokens with Neural Engine acceleration, typically completing a 512-token generation in under 250ms total latency. Cloud APIs introduce network round-trip time on top of generation time (Apple Developer Docs):
| Provider | Time to First Token | Notes |
|---|---|---|
| Apple Foundation Models | <50ms (on-device Neural Engine) | Local, no network |
| MiniMax M2.7 | 0.3–1.5s | Optimized for speed |
| GPT-4o | 0.8–2.5s | Network + compute |
| Claude Sonnet 4.6 | 1.0–3.5s | Higher quality, higher latency |
For real-time features like voice transcription or live assistance, sub-100ms on-device response is noticeable. For async features like summary generation, 1–2 second cloud latency is acceptable — but a 10x latency difference matters for interactive use cases.
Capability Comparison: MMLU Benchmarks
On-device models are smaller and more limited than frontier cloud models. The MMLU benchmark (Massive Multitask Language Understanding, Hendrycks et al., 2020) provides a standardized comparison:
| Model | MMLU Score | Context Window | Parameters |
|---|---|---|---|
| Apple AFM (on-device) | ~73.2% | 4,096 tokens | ~3B |
| Claude Sonnet 4.6 | 88.1% | 200K tokens | ~70B |
| GPT-4o | 86.4% | 128K tokens | ~200B |
| MiniMax M2.7 | ~81.0% | 1M tokens | ~100B |
| Claude Haiku 3.5 | 75.2% | 200K tokens | ~30B |
MMLU scores from published model cards and HELM benchmark (crfm.stanford.edu/helm, 2026). Apple AFM score from Apple Developer Documentation.
Capability Matrix
| Capability | Apple FM | Cloud LLMs |
|---|---|---|
| Text generation | Yes | Yes |
| Code generation | Basic | Advanced |
| Multimodal (image input) | Limited | Yes |
| Offline support | Yes | No |
Privacy: The Decisive Factor
Privacy isn't just a feature — it's a competitive advantage, especially for sensitive domains (Apple Developer Docs):
Apple Foundation Models
- • All inference happens on-device — data never leaves the user's hardware
- • No API calls means no data logged by third parties
- • Apple does not receive prompts or outputs from your app
- • Works in airplane mode with full functionality
- • Apple Silicon's Secure Enclave provides hardware-level isolation
Cloud LLMs
- • User data transmitted to third-party servers for inference
- • API providers may log inputs for model improvement purposes
- • Data handling varies by provider tier (consumer vs enterprise)
- • Requires internet connectivity — no offline capability
- • Subject to provider's data retention policies
"For applications handling protected health information (PHI) or financial data, on-device inference eliminates an entire category of compliance risk. Cloud APIs introduce data residency and third-party processing concerns that require legal review in regulated industries."
For health apps, financial tools, or any app handling personal data, on-device processing is a significant trust signal. Research from the HELM benchmark project confirms that privacy requirements drive adoption of on-device models in 38% of surveyed enterprise AI deployments.
When to Use Apple Foundation Models
- • Privacy-sensitive apps — Health, finance, personal journaling: data stays on-device
- • Offline-first features — Need to work without connectivity
- • High-volume, simple tasks — Summarization, classification, extraction at scale
- • Cost-sensitive projects — API costs become prohibitive at 100K+ MAU
- • Sub-second latency required — Real-time voice assistance, live transcription
- • Consumer apps — You don't control user device capabilities or OS versions
When to Use Cloud LLMs
- • Complex reasoning — Multi-step analysis, advanced coding (HumanEval 85%+ vs Apple AFM ~52%)
- • Long context — Processing documents over 4,096 tokens (Apple AFM limit)
- • Specialized tasks — Scientific analysis, mathematical reasoning, code generation
- • Multimodal beyond images — Video, audio processing
- • Server-side processing — You control the infrastructure and data pipeline
- • Consistent behavior — Deterministic outputs across all user devices
The Hybrid Approach
Many production apps use both — the architecture that LM Arena ranks highest on user preference combines local generation with cloud judgment. A typical hybrid setup (RAGAS: Raj et al., 2023):
- On-device generation — 80% of requests handled by Apple Foundation Models (free, private, fast)
- Cloud fallback — Route to GPT-4o or Claude when Apple FM confidence is low
- On-device generation, cloud judging — Use LLM Eval Suite with MiniMax as judge to evaluate Apple FM outputs without logging data to cloud services
Requirements: Can You Use Apple FM?
- • macOS 26.0 or later — Required for Foundation Models framework access
- • Apple Silicon Mac — M1, M2, M3, or M4 series; Neural Engine required
- • Apple Intelligence enabled — Enrolled in System Settings > Apple Intelligence
- • 8GB RAM minimum — 16GB recommended for production use
The Decision Framework
Use this decision tree — each question corresponds to a dimension where Apple FM and cloud LLMs diverge significantly:
- Is the data sensitive? → Apple FM (privacy, no third-party transmission)
- Does it need to work offline? → Apple FM (fully local)
- Is the task complex reasoning (MMLU <75%)? → Cloud LLM (Apple AFM ~73.2%)
- Do you need >4,096 token context? → Cloud LLM (Apple AFM limit)
- Will API costs exceed $500/month at scale? → Apple FM ($0 API cost)
- Is sub-500ms latency required for real-time interaction? → Apple FM (<50ms vs 500ms+ cloud)
Get Started
Ready to evaluate Apple Foundation Models against cloud alternatives? Learn how to evaluate Apple Foundation Models on your Mac to measure real-world quality against your specific use case. Understand the scoring metrics that drive evaluation — faithfulness, actionability, completeness, and hallucination — and see how LLM benchmarks provide standardized comparison data.
Try LLM Eval Suite
Evaluate both Apple Foundation Models and cloud LLMs with structured scoring.
Download on Mac App Store