
Use Cases
LLM Eval Suite Use Cases: From Prompt Testing to Production Confidence
Practical ways teams can use structured evaluation to compare prompts, validate outputs, and improve AI features before users find the weak spots.
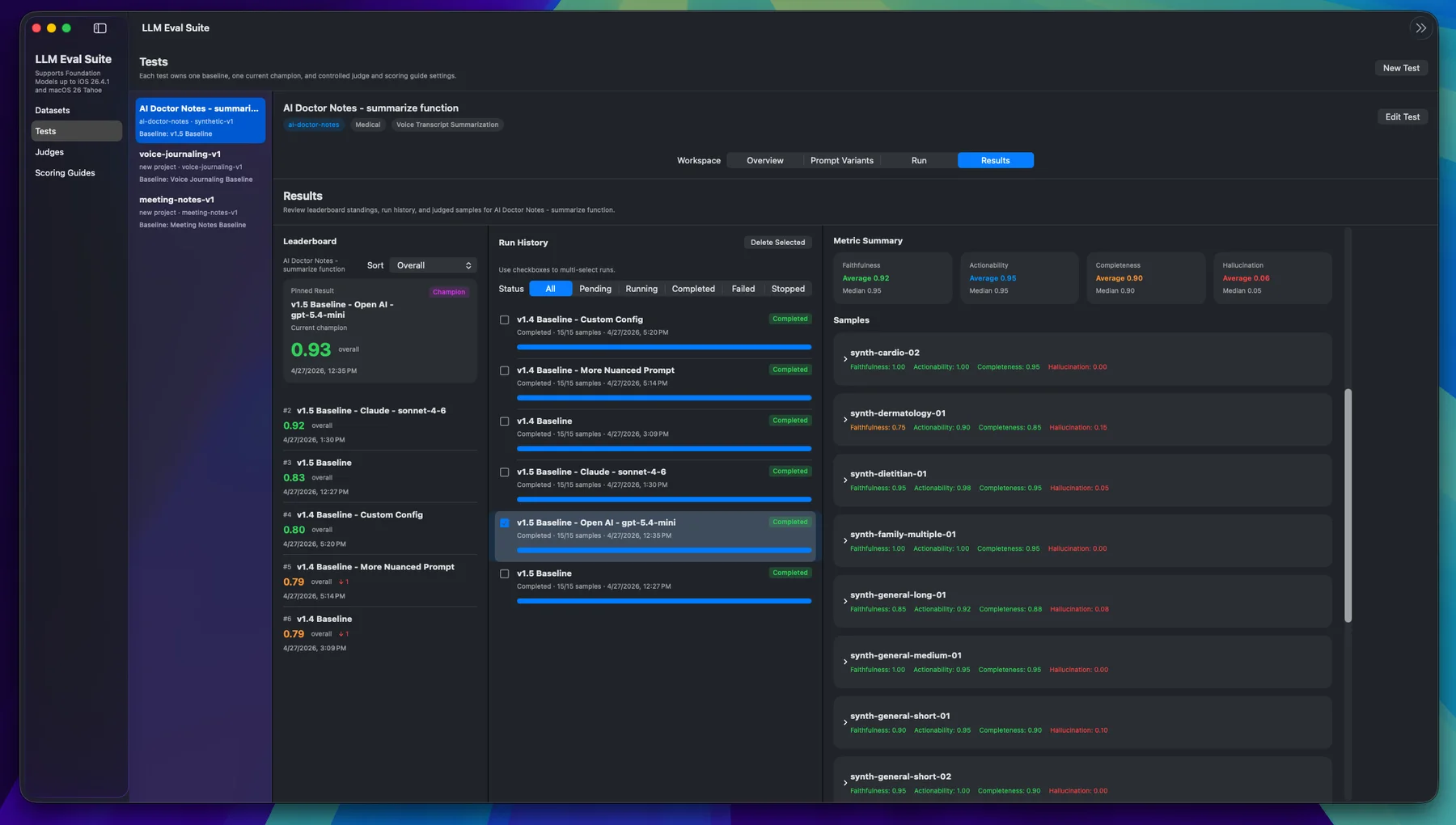
LLM Eval Suite is most useful when an AI feature has moved past a demo and needs repeatable evidence. Instead of asking whether a single output looks good, you can evaluate many realistic inputs across the same scoring dimensions and compare results over time.
We wrote a full Medium case study about using LLM Eval Suite to improve AI Doctor Notes. This local guide gives the quick use-case map, then links to the original article for the complete walkthrough.
Original case study
How we used LLM Eval Suite to build a better AI feature in AI Doctor Notes
The Medium article walks through the real product problem, evaluation setup, prompt variants, scoring approach, and the improvement process.
Read the original on MediumCommon use cases
Transcript Summarization Evaluation
Voice journals, call recordings, and interview transcripts are prone to hallucination and omission. Evaluate whether summaries stay faithful to the source, capture key points, and remain actionable.
Meeting Notes and Action Items
Meeting summaries need to capture decisions, action items, and commitments accurately. Use structured evaluation to compare different prompt strategies before rolling out a new meeting AI feature.
Apple Foundation Models vs Cloud Model Comparison
Compare outputs from Apple Foundation Models against GPT or Claude side-by-side using the same dataset and scoring guide. Measure quality, latency, and cost tradeoffs with repeatable data.
Prompt Regression Testing
When you update a prompt or change a model, run your evaluation suite to catch regressions before release. Track scores across iterations in the leaderboard to see whether changes actually improved quality.
AI QA for Production Features
Add structured evaluation to your release checklist for AI features. Run a representative dataset through your prompt variants and verify scores meet threshold before shipping.
When to use structured evaluation
Use structured evaluation when subjective spot checks are no longer enough: medical notes, meeting summaries, voice journals, customer support drafts, knowledge-base answers, and any workflow where hallucination or missing context can erode trust.
The goal is not to replace human judgment. The goal is to make quality visible earlier, so product teams can compare versions with a shared rubric instead of relying on vibes, screenshots, or one-off examples.
For a deeper look at why structured evaluation catches failure modes that informal testing misses, read our guide to structured evaluation importance. To understand how judges score outputs, see LLM-as-a-judge evaluation.